

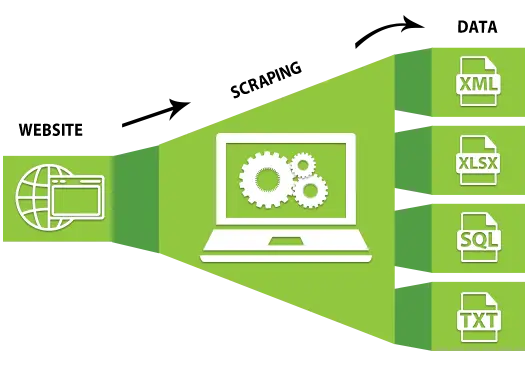

Sahabat Teckknow kita akan membahas tentang Teknologi Scrape Data, dalam era digital yang semakin berkembang, data menjadi salah satu aset paling berharga. Data dapat memberikan wawasan yang mendalam tentang berbagai aspek kehidupan, mulai dari preferensi konsumen hingga tren pasar. Salah satu teknologi yang telah merevolusi cara kita mengumpulkan data adalah teknologi scrape data atau web scraping.
Apa itu Scrape Data?
Teknologi Scrape Data adalah teknik untuk mengekstraksi informasi dari situs web secara otomatis. Dengan menggunakan perangkat lunak atau skrip tertentu, pengguna dapat mengunduh dan mengumpulkan data dari berbagai sumber online tanpa perlu melakukannya secara manual. Proses Teknologi Scrape Data melibatkan pengambilan konten dari halaman web, seperti teks, gambar, atau tabel, dan menyimpannya dalam format yang dapat dianalisis lebih lanjut, seperti CSV atau database.
Bagaimana Cara Kerja Scrape Data?
Proses scrape data biasanya melibatkan beberapa langkah utama:
- Mengirim Permintaan HTTP: Skrip web scraping mengirimkan permintaan HTTP ke situs web target untuk mengakses halaman tertentu.
- Mengambil Konten Halaman: Setelah menerima respons dari server, skrip akan mengambil konten halaman, yang biasanya dalam format HTML.
- Memilah Data yang Diinginkan: Menggunakan pustaka pemrosesan HTML seperti BeautifulSoup (Python) atau Cheerio (JavaScript), skrip akan memilah dan mengekstrak data yang relevan dari konten HTML.
- Menyimpan Data: Data yang telah diekstraksi kemudian disimpan dalam format yang diinginkan, seperti CSV, JSON, atau langsung ke database.
Teknologi dan Alat untuk Scrape Data
Teknologi Scrape Data adalah teknik yang memerlukan alat dan pustaka tertentu untuk mengotomatiskan proses pengumpulan data dari situs web. Berikut adalah beberapa teknologi dan alat yang populer dan sering digunakan dalam web scraping:
1. BeautifulSoup
Deskripsi: BeautifulSoup adalah pustaka Python yang dirancang untuk mengurai (parse) dokumen HTML dan XML. Alat ini memudahkan pengekstrakan data dengan menyediakan metode yang intuitif untuk menavigasi dan mencari elemen dalam struktur dokumen.
Kelebihan:
- Mudah digunakan dan dipelajari, cocok untuk pemula.
- Dapat mengurai dokumen HTML yang tidak sempurna (malformed).
- Mendukung pencarian elemen dengan metode CSS selectors dan navigasi tree traversal.
Penggunaan: BeautifulSoup sering digunakan untuk proyek scraping yang relatif kecil dan sederhana. Contohnya, mengekstrak data dari blog, artikel berita, atau tabel data di halaman web.
Contoh Kode:
from bs4 import BeautifulSoup
import requestsresponse = requests.get(url)
soup = BeautifulSoup(response.text, ‘html.parser’)
# Menemukan semua tautan di halaman
for link in soup.find_all(‘a’):
print(link.get(‘href’))
2. Scrapy
Deskripsi: Scrapy adalah kerangka kerja (framework) web scraping yang kuat dan serbaguna, juga ditulis dalam Python. Scrapy dirancang untuk pengikisan web yang cepat dan berskala besar.
Kelebihan:
- Sangat cepat dan efisien dalam mengikis data.
- Mendukung penanganan permintaan asinkron, memungkinkan scraping paralel.
- Dilengkapi dengan berbagai fitur built-in seperti penanganan cookie, redirection, dan limitasi crawling.
- Mendukung pemrosesan data yang kompleks dan pipeline data.
Penggunaan: Scrapy cocok untuk proyek scraping yang kompleks dan berskala besar, seperti mengumpulkan data dari situs e-commerce, agregasi berita, dan proyek analisis data yang memerlukan scraping dari banyak situs web.
Contoh Kode:
import scrapy
class ExampleSpider(scrapy.Spider):
name = ‘example’
start_urls = [‘http://example.com’]
def parse(self, response):
for href in response.css(‘a::attr(href)’).extract():
yield {‘URL’: href}
3. Selenium
Deskripsi: Selenium adalah alat otomatisasi yang dapat mengontrol browser web. Selenium sering digunakan untuk scraping situs web dinamis yang memuat konten melalui JavaScript, yang tidak dapat diakses dengan mudah oleh pustaka HTTP biasa.
Kelebihan:
- Dapat mengontrol browser nyata seperti Chrome, Firefox, dan lain-lain.
- Dapat menangani situs web yang dinamis dan interaktif.
- Mendukung pengujian fungsional otomatis selain scraping.
Penggunaan: Selenium sangat berguna untuk scraping situs web yang menggunakan AJAX untuk memuat data atau situs yang memerlukan interaksi pengguna seperti login atau pengisian formulir.
Contoh Kode:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(‘http://example.com’)
# Mengambil elemen berdasarkan Xpath
elements = driver.find_elements_by_xpath(‘//a’)
for element in elements:
print(element.get_attribute(‘href’))
driver.quit()
4. Puppeteer
Deskripsi: Puppeteer adalah pustaka Node.js yang menyediakan API tingkat tinggi untuk mengontrol Chrome atau Chromium melalui Protokol DevTools. Puppeteer sangat cocok untuk mengotomatiskan interaksi browser dan Teknologi Scrape Data konten yang dimuat oleh JavaScript.
Kelebihan:
- Memberikan kontrol penuh atas browser tanpa kepala (headless browser).
- Dapat menangani situs web yang kompleks dan dinamis.
- Mendukung pembuatan screenshot dan PDF dari halaman web.
Penggunaan: Puppeteer sering digunakan untuk scraping data dari situs web yang sangat dinamis, membuat tes end-to-end, dan menghasilkan laporan visual dari halaman web.
Contoh Kode:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(‘http://example.com’);
// Mengambil semua URL dari halaman
const links = await page.evaluate(() =>
Array.from(document.querySelectorAll(‘a’), a => a.href)
);
console.log(links);
await browser.close();
})();
Aplikasi Scrape Data
Teknologi Scrape Data digunakan dalam berbagai bidang dan industri, termasuk:
- E-commerce: Mengumpulkan informasi harga dan produk dari situs web pesaing untuk analisis kompetitif.
- Pemasaran Digital: Menyusun data dari berbagai platform media sosial untuk menganalisis tren dan sentimen publik.
- Penelitian Akademik: Mengambil data dari publikasi online dan sumber akademik untuk analisis lebih lanjut.
- Jurnalisme: Mengumpulkan data dari sumber berita dan situs web resmi untuk investigasi dan pelaporan.
Tantangan dan Etika dalam Scrape Data
Meskipun teknologi scrape data sangat berguna, ada beberapa tantangan dan pertimbangan etika yang perlu diperhatikan:
- Legalitas: Tidak semua situs web mengizinkan scraping. Penggunaan scrape data harus mematuhi hukum dan kebijakan situs web yang bersangkutan.
- Kinerja: Scraping yang berlebihan dapat membebani server situs web target, menyebabkan kinerja yang buruk atau bahkan pemblokiran.
- Keamanan Data: Mengambil dan menyimpan data sensitif harus dilakukan dengan mempertimbangkan keamanan dan privasi data.
Kesimpulan
Teknologi scrape data telah membuka banyak peluang untuk pengumpulan dan analisis data di berbagai bidang. Dengan alat dan teknik yang tepat, scrape data dapat memberikan wawasan berharga yang membantu dalam pengambilan keputusan bisnis, penelitian, dan banyak lagi. Namun, penting untuk selalu memperhatikan aspek legal dan etika dalam menggunakan Teknologi Scrape Data, memastikan bahwa kita memanfaatkannya dengan cara yang bertanggung jawab dan berkelanjutan.

